DataFrame.pivot(self, index=None, columns=None, values=None) → 'DataFrame' [source]
返回按给定索引/列值组织的重新构造的DataFrame。
根据列值重塑数据(生成一个 "pivot" 表)。使用来自指定索引/列的惟一值来形成结果DataFrame的轴。此函数不支持数据聚合,多个值将导致列中的多索引。更多关于整形的信息,请参阅User Guide 。
参数: | index : 用于制作新 columns : 位置参数传递给 values : 于填充新frame值的列。如果未指定,将使用所有剩余的列,并且结果将具有按层次结构索引的列。 在版本0.23.0中更改:还接受列名称列表。 |
返回值: |
返回调整后的 |
Raises: | ValueError: 如果有任何 |
Notes
有关更好的控制,请参阅分层索引文档以及相关的堆栈/非堆栈方法。
例子
>>> df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two',... 'two'],... 'bar': ['A', 'B', 'C', 'A', 'B', 'C'],... 'baz': [1, 2, 3, 4, 5, 6],... 'zoo': ['x', 'y', 'z', 'q', 'w', 't']})>>> df foo bar baz zoo0 one A 1 x1 one B 2 y2 one C 3 z3 two A 4 q4 two B 5 w5 two C 6 t>>> df.pivot(index='foo', columns='bar', values='baz')bar A B Cfooone 1 2 3two 4 5 6
>>> df.pivot(index='foo', columns='bar')['baz']bar A B Cfooone 1 2 3two 4 5 6
>>> df.pivot(index='foo', columns='bar', values=['baz', 'zoo']) baz zoobar A B C A B Cfooone 1 2 3 x y ztwo 4 5 6 q w t
如果存在重复项,则会引发ValueError
>>> df = pd.DataFrame({"foo": ['one', 'one', 'two', 'two'],... "bar": ['A', 'A', 'B', 'C'],... "baz": [1, 2, 3, 4]})>>> df foo bar baz0 one A 11 one A 22 two B 33 two C 4注意 : 前两行对于我们的index 和column参数是相同的
>>> df.pivot(index='foo', columns='bar', values='baz')Traceback (most recent call last): ...ValueError: Index contains duplicate entries, cannot reshape
免责声明:以上内容(如有图片或视频亦包括在内)有转载其他网站资源,如有侵权请联系删除
-
设计总结|如何更好地表达活动品牌?


-

谈谈“目标思维”的落地
编辑导读:我们在做数据分析之前,一定要搞清楚需求方的目标到底是什么,要根据目标来重新定义业务方提出的问题,这就是目标思维。目标思维有多重要呢?应该如何落地呢...
-
在线教育平台竞品分析:网易云课堂vs腾讯课堂
本文从移动端出发,对当前比较热门的两款在线教育平台软件-网易云课堂和腾讯课堂进行比较和分析,不足之处还请大家多提意见。 市场分析 随着国内互联网技术的发展和移...
-
即学即用|父亲节活动的4种运营策略



-
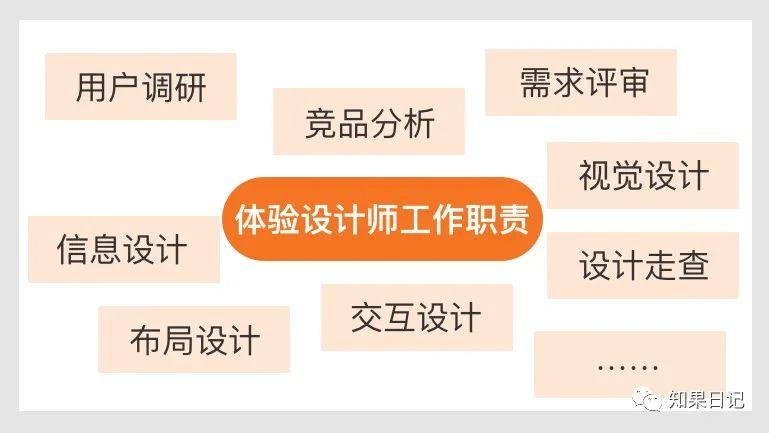
B端产品经理和体验设计师的工作职责边界梳理


-
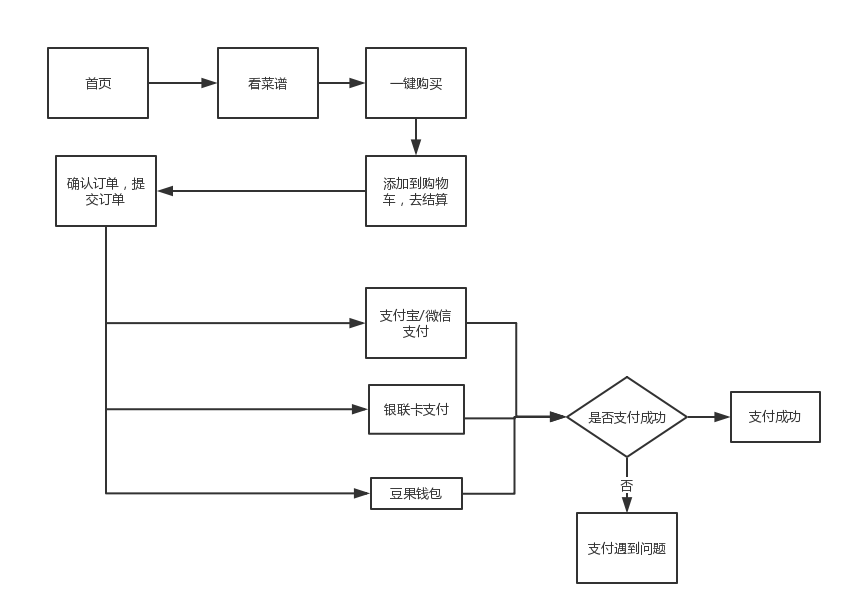
豆果美食电商分支用户体验报告及建议

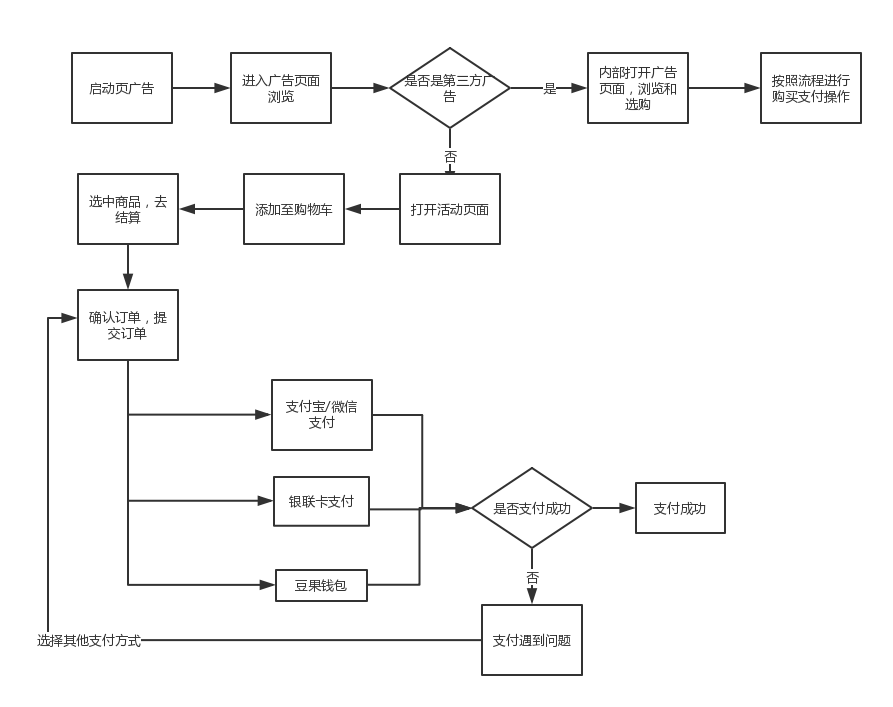
-

数据分析师如何提高工作效率
在我们的日常工作中,提高工作效率是每个岗位都需要实现的,在工作中,面对比较凌乱的事情时,首先我们需要梳理清楚,按重要级进行开展;本文作者分享了关于...
-
2016中国云计算SaaS移动办公平台年度综合报告

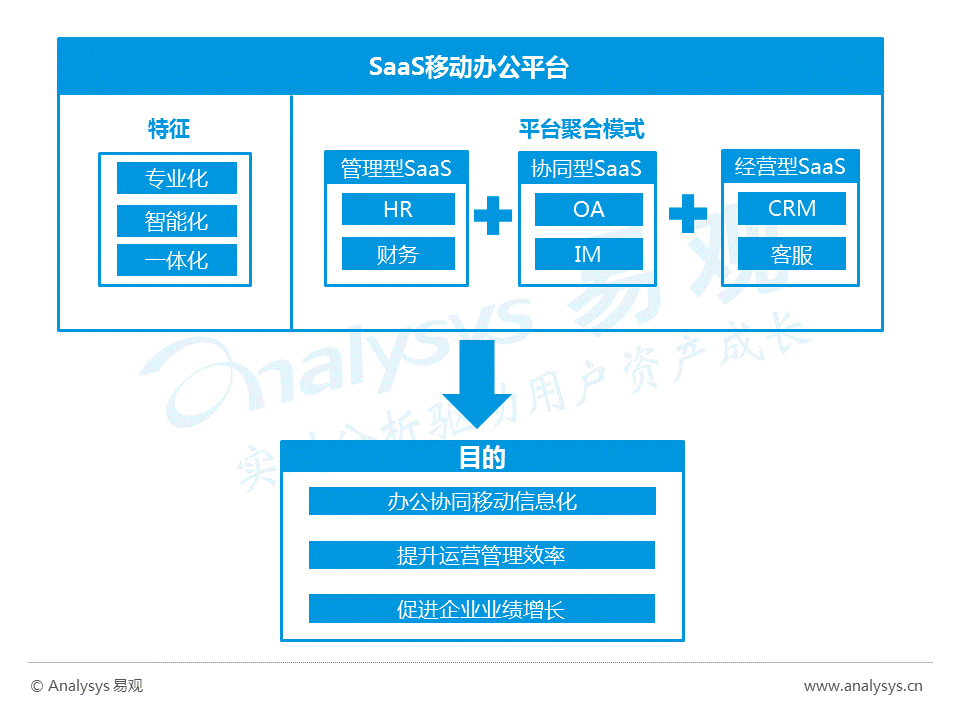
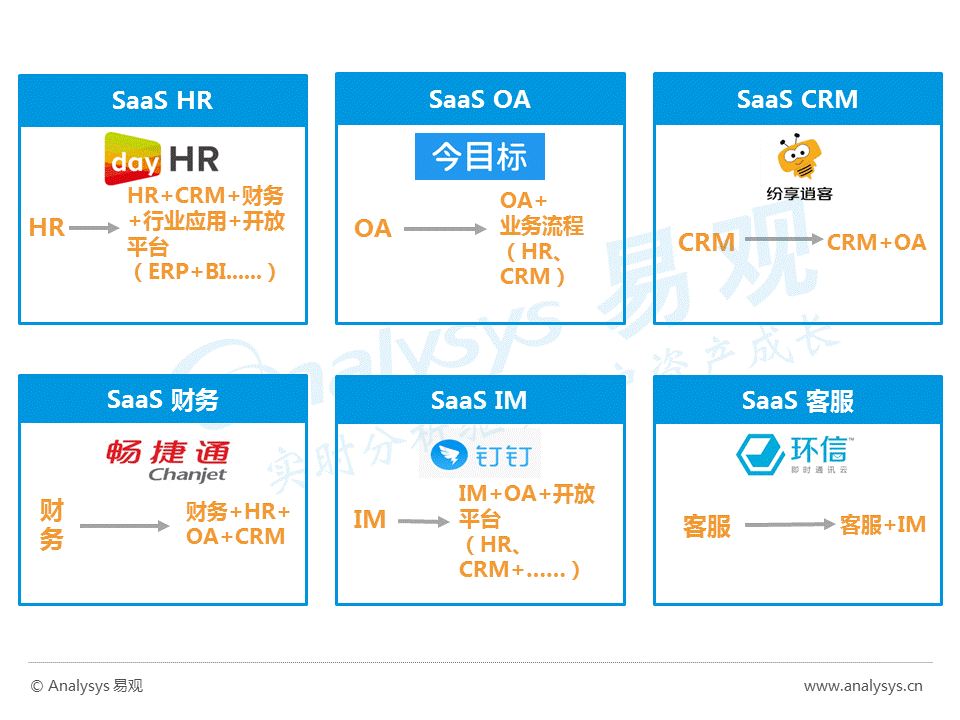
-
网易大布局教育事业:网易公开课、网易云课堂和MOOC分析

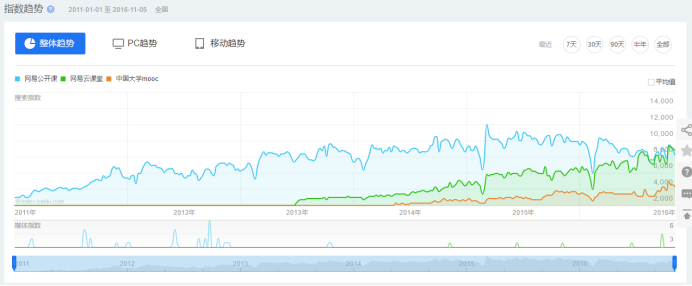
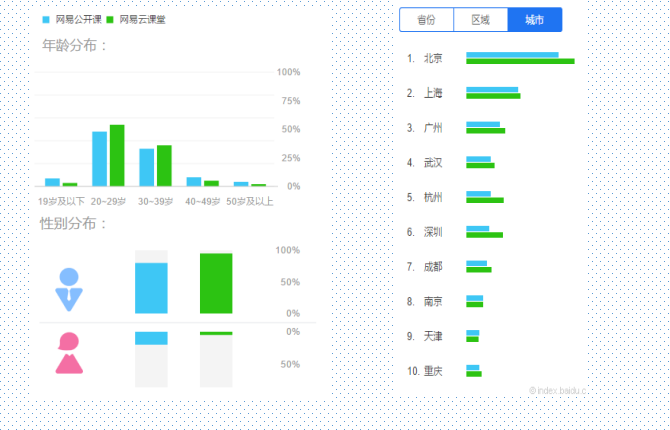
-
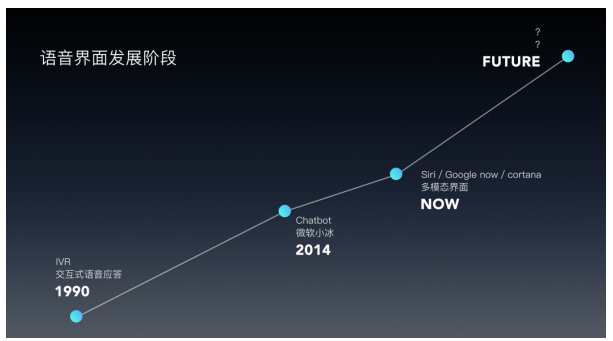
一篇文章搞懂语音交互的来龙去脉