SparkContext是任何spark功能的入口点.当我们运行任何Spark应用程序时,会启动一个驱动程序,它具有main函数,并且此处启动了SparkContext.然后,驱动程序在工作节点上的执行程序内运行操作.
SparkContext使用Py4J启动 JVM 并创建 JavaSparkContext .默认情况下,PySpark将SparkContext作为'sc'提供,因此创建新的SparkContext将不起作用.
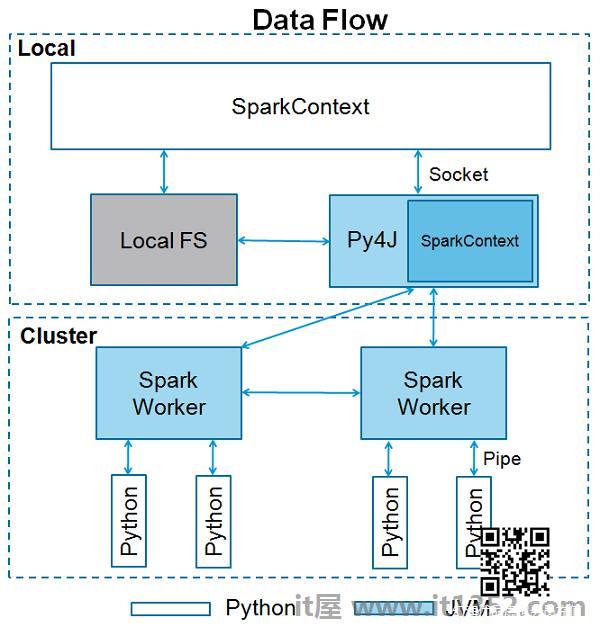
以下代码块包含PySpark类的详细信息以及SparkContext可以采用的参数.
class pyspark.SparkContext ( master = None, appName = None, sparkHome = None, pyFiles = None, environment = None, batchSize = 0, serializer = PickleSerializer(), conf = None, gateway = None, jsc = None, profiler_cls = <class 'pyspark.profiler.BasicProfiler'>)
参数
以下是SparkContext的参数.
Master : 它是它所连接的群集的URL.
appName : 你的工作名称.
sparkHome : Spark安装目录.
pyFiles : 要发送到集群并添加到PYTHONPATH的.zip或.py文件.
环境 : 工作节点环境变量.
batchSize : 表示为单个Java对象的Python对象数.设置1以禁用批处理,设置为0以根据对象大小自动选择批处理大小,或设置为-1以使用无限制的批处理大小.
序列化程序 : RDD序列化器.
Conf : L {SparkConf}的一个对象,用于设置所有Spark属性.
网关 : 使用现有网关和JVM,否则初始化新JVM.
JSC : JavaSparkContext实例.
profiler_cls : 用于分析的一类自定义Profiler(默认为pyspark.profiler.BasicProfiler).
在上述参数中,<b主人和 appname 主要使用.任何PySpark程序的前两行看起来如下所示 :
from pyspark import SparkContextsc = SparkContext("local", "First App")SparkContext示例 - PySpark Shell
现在您已经了解了SparkContext,请告诉我们在PySpark shell上运行一个简单的例子.在此示例中,我们将计算 README.md 文件中带有字符"a"或"b"的行数.那么,让我们说一个文件中有5行,3行有'a'字符,那么输出将是 → 与a:3 对齐.字符'b'也是如此.
注意 : 我们没有在以下示例中创建任何SparkContext对象,因为默认情况下,当PySpark shell启动时,Spark会自动创建名为sc的SparkContext对象.如果您尝试创建另一个SparkContext对象,您将收到以下错误 - "ValueError:无法一次运行多个SparkContexts".
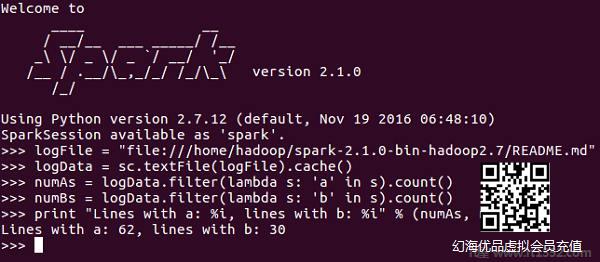
<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"<<< logData = sc.textFile(logFile).cache()<<< numAs = logData.filter(lambda s: 'a' in s).count()<<< numBs = logData.filter(lambda s: 'b' in s).count()<<< print "Lines with a: %i, lines with b: %i" % (numAs, numBs)Lines with a: 62, lines with b: 30
SparkContext示例 - Python程序
让我们使用Python程序运行相同的示例.创建一个名为 firstapp.py 的Python文件,并在该文件中输入以下代码.
----------------------------------------firstapp.py---------------------------------------from pyspark import SparkContextlogFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md" sc = SparkContext("local", "first app")logData = sc.textFile(logFile).cache()numAs = logData.filter(lambda s: 'a' in s).count()numBs = logData.filter(lambda s: 'b' in s).count()print "Lines with a: %i, lines with b: %i" % (numAs, numBs)----------------------------------------firstapp.py---------------------------------------然后我们将在终端中执行以下命令来运行这个Python文件.我们将得到与上面相同的输出.
$SPARK_HOME/bin/spark-submit firstapp.pyOutput: Lines with a: 62, lines with b: 30
免责声明:以上内容(如有图片或视频亦包括在内)有转载其他网站资源,如有侵权请联系删除
-
设计总结|如何更好地表达活动品牌?


-

谈谈“目标思维”的落地
编辑导读:我们在做数据分析之前,一定要搞清楚需求方的目标到底是什么,要根据目标来重新定义业务方提出的问题,这就是目标思维。目标思维有多重要呢?应该如何落地呢...
-
在线教育平台竞品分析:网易云课堂vs腾讯课堂
本文从移动端出发,对当前比较热门的两款在线教育平台软件-网易云课堂和腾讯课堂进行比较和分析,不足之处还请大家多提意见。 市场分析 随着国内互联网技术的发展和移...
-
即学即用|父亲节活动的4种运营策略



-
B端产品经理和体验设计师的工作职责边界梳理


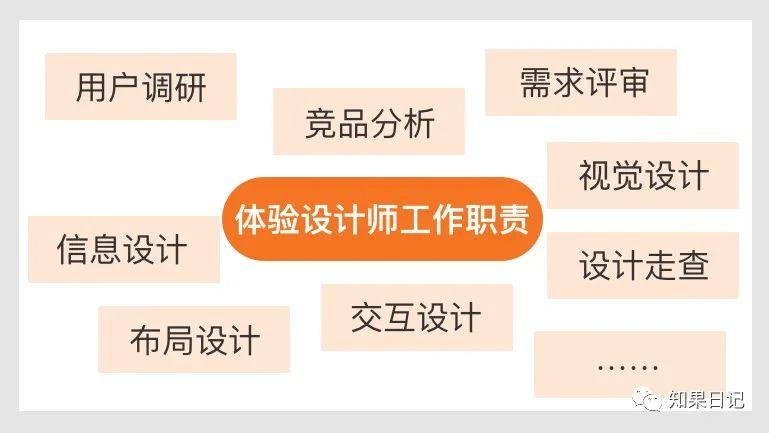
-
豆果美食电商分支用户体验报告及建议

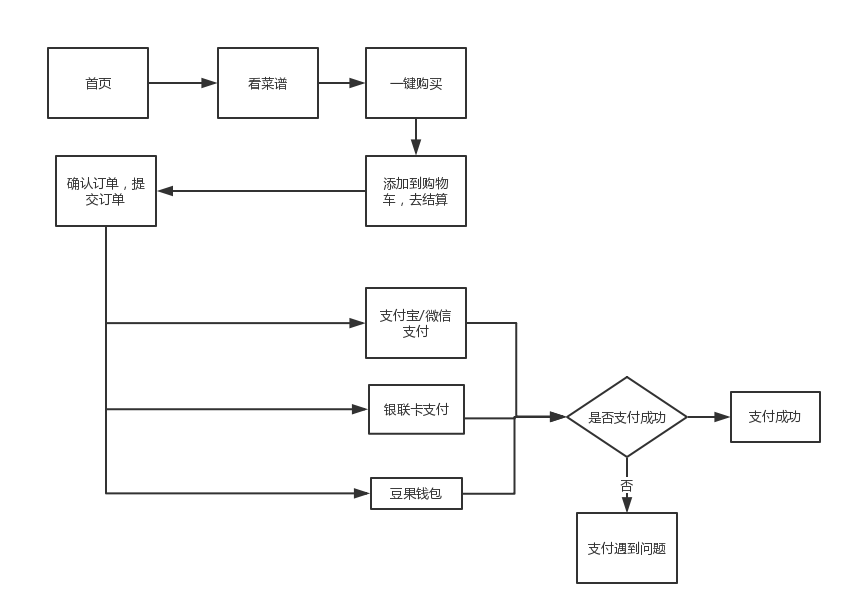
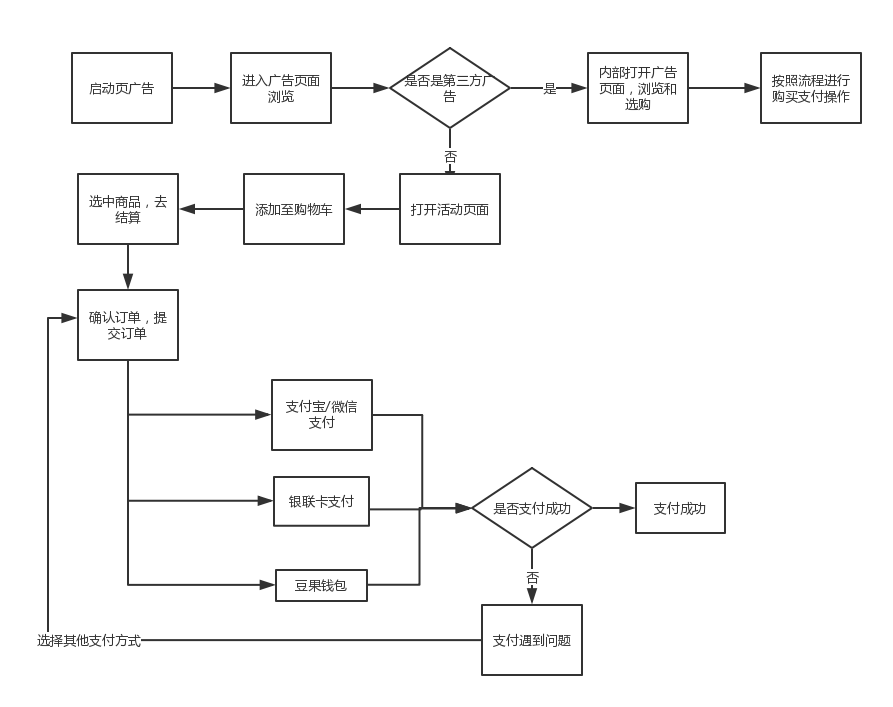
-

数据分析师如何提高工作效率
在我们的日常工作中,提高工作效率是每个岗位都需要实现的,在工作中,面对比较凌乱的事情时,首先我们需要梳理清楚,按重要级进行开展;本文作者分享了关于...
-
2016中国云计算SaaS移动办公平台年度综合报告

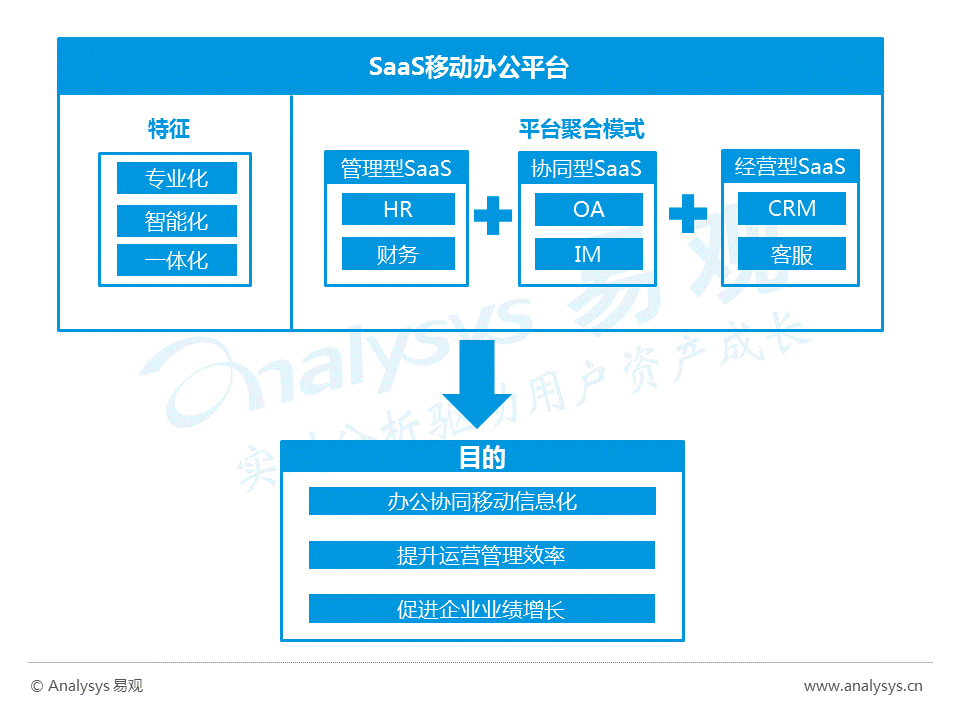
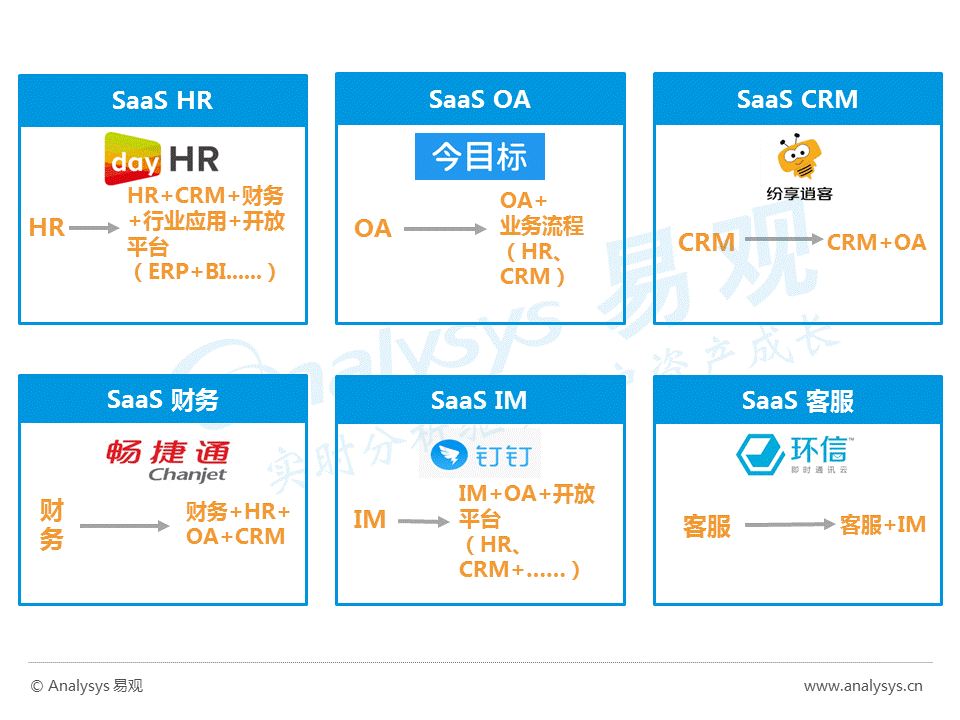
-
网易大布局教育事业:网易公开课、网易云课堂和MOOC分析

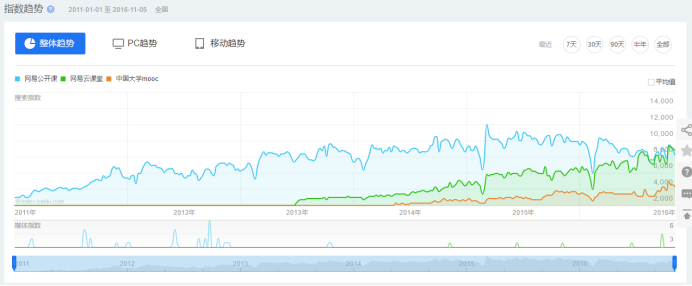
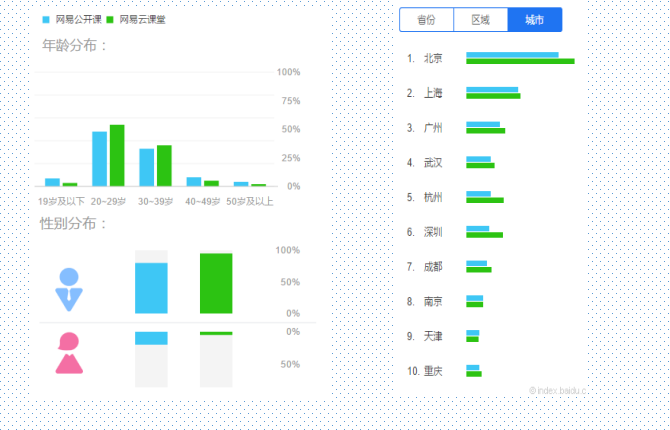
-
一篇文章搞懂语音交互的来龙去脉